이 글에 대해
대학생 시절 java와 C# .net이 더 유행하던 시절에 openCV를 하겠다고, 정말 환경세팅부터 코딩까지 꽤나 힘들었는데....
유튜브를 보니 정말 파이썬으로 뚝딱이여서, 유튜브를 파이썬으로 따라 해보고 느낀점을 적어보았습니다.
환경적 요인에 약한 이미지 프로세싱
그림자, 비가 오는 날, 해가 뜨기 시작하는 새벽, 해가 다 뜬 낮, 주변 불빛이 많은 저녁,
노을 진 하늘, 진눈깨비 및 안개로 인한 시야 흐림, 진흙 혹은 벌레로 인한 번호판 가림 등
이러한 모든 상황에 어느 정도 대비는 해야 합니다.
사실 이러한 상황일 때 주차장에서 번호판 인식이 안 되면, 차를 앞-뒤로 움직여서 다시 찍히게 만들었던 기억이 나네요.
번호판 종류
한국에는 정말 많은 번호판 종류가 있습니다.






시대에 따라서 글자를 사람이 잘 볼 수 있게 초록색 배경에서 흰색 배경으로 바꾸고
지역감정을 없애기 위해서 지역을 빼고, 지나고 보니 차가 계속 생산되는데 번호판 한계가 있어서 숫자를 늘리고.....
이러한 시대적 변화로 인해 번호판 인식 프로그래밍을 계속해서 맞춰가야 합니다.
또한, 특수목적용 번호판 양식도 다 별도로 구현해야 합니다... 윽..
(한국 차량 번호판 wiki : https://namu.wiki/w/%EC%B0%A8%EB%9F%89%20%EB%B2%88%ED%98%B8%ED%8C%90/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD)
구현 방법
여러번 이야기하는 거지만, 진짜 요즘엔 python으로 openCV를 이용한 방법이 많아서 너무 구현하기 쉽네요
원리는 간단 합니다.
1. 글자 영역 찾기
2. 판독이 잘 되게 이미지 다듬기 (회전,자르기 등)
(잘... 되게 하기가 힘듭니다)
3. OCR (문자판독) 거쳐서 글자 획득
요즘엔 머신러닝으로 학습을 시켜서, 조금 더 확률이 높은 데이터를 반환해서 보정하는 방법을 많이 쓰고 있었습니다.
이미지 프로세싱 세부 단계
유튜브, github 을 보고 따라 해보았고,
자세한 과정은 아래를 참고해주세요.
참고) https://github.com/kairess/license_plate_recognition/blob/master/main.ipynb
1) 이미지 준비

2) 흑백으로 변경 (Grayscale)

흑백으로 변경하되, 특정 상황(특히 어두운 밤에 밝은 전조등이 켜진 상황)으로 인해 카메라에 찍힌 사진이 흐릴 경우,
강조 시켜 보이기 위해, TopHat (어두운 배경에서 밝게 강조), BlackHat(BottomHat, 밝은 배경에서 어둡게 강조)하는 방법을 사용한
이미지까지 합친다면, 더 좋은 상태의 텍스트(번호판의 번호)를 추출해 낼 수 있습니다.
3) 색상과 색상의 경계 두드러지게 하기 (Thresholding)
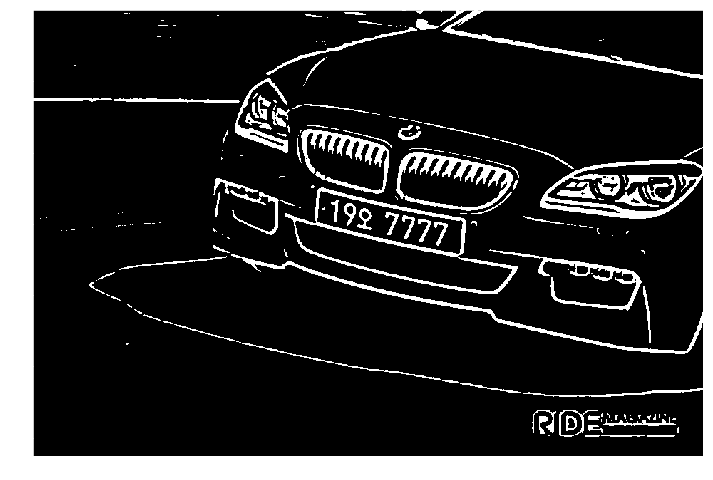
작은 사이즈마다 변환하는 Thresholding도 좋지만
전체적인 사진을 만지는 Adobe PhotoShop의 Level 변환 기능을 이용하면 더 좋은 이미지를 뽑아낼 수 있습니다.
Level기능은 Brightness와 Contrast Adjustments로 이뤄져 있는 듯합니다.
하지만 python에서 이를 구현해서 오픈한 사람이 없으니 그냥 thresholding을 쓰는 게 나을 거 같습니다.
thresholding 사이즈에 따라서 contour가 다르게 동작할 수 있으니, 사이즈를 가변 할 수 있게 코딩해야 합니다
4) 색이 연결된 부분을 그룹화 하기 (Contour)
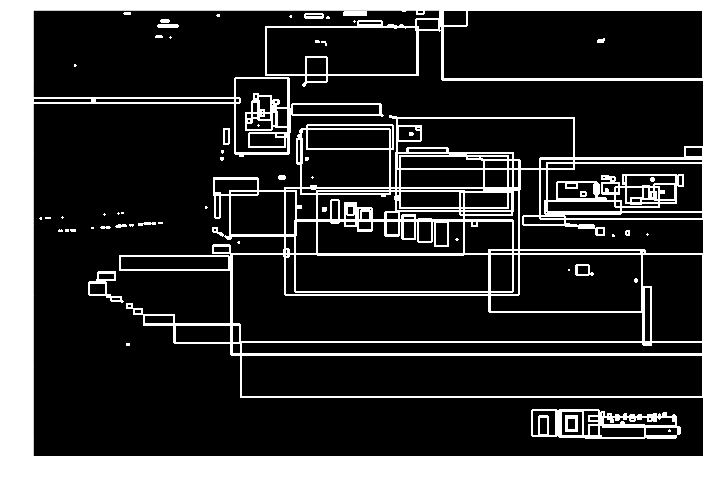
5) 그룹화된 부분마다 자동차 번호판 체계에 맞는 서체 비율 판단하기
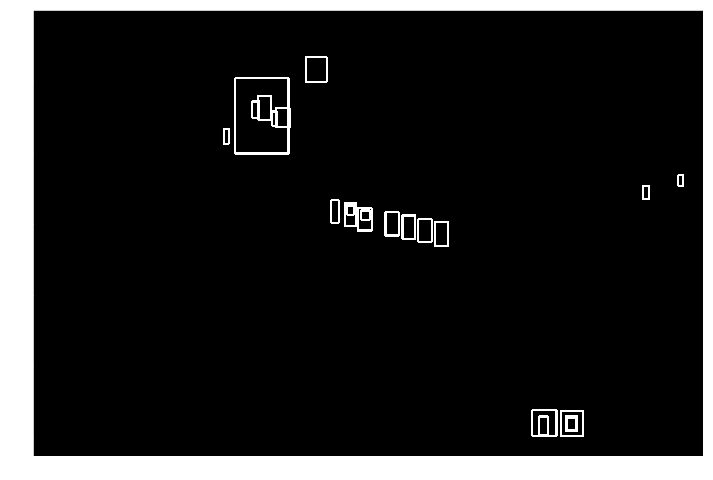
가로-세로 비율을 따져서, 서체에 맞지 않는 비율을 제거하니 contour가 몇 개 안 남네요.
6) Contour의 근접한 Contour가 번호판 체계에 맞는 배치도인지 판단하기
(예. 서울23나1234, 12가1234 등)

서울23나1234 같은 경우는 2줄,
12가1234는 1줄로 된 번호판 형태입니다.
7) 번호판 범위 정하기

6번 차례에서 보면 인식된 contour는 5개지만,
인식된 첫 번째가 실제 글자의 첫번째 글자가 될 수 도 있고,
첫번째 글자가 인식이 안돼서 두 번째 글자부터 인식된 걸 수도 있습니다.
그래서 범위를 정~~~말 잘 정해야 됩니다..
8) 글자 회전

기울어진 배치도를 일반 글자의 각도로 맞춰줍니다.
Z축 회전도 회전이지만, X, Y축도 신경 써주면 더 좋아 집니다.
9) 최종 이미지를 통해 문자 인식하기
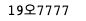
무엇보다도 한글을 인식(OCR)하려면, 한글 문자인식 학습 데이터가 필요합니다.
주로 오픈소스로는 HP에서 만든 학습 데이터를 사용하게 됩니다.
10) 인식된 글자
인식이 끝나면, 인식된 글자+숫자를 반환하게 됩니다.
사용된 코드
$python ./car12_ex1.py web_1.jpg 11
car12_ex.py파일을 실행시키고, 이미지 파일명을 첫번째 인자로 전달합니다.
그리고 두번째 인자로 가우시안 블러 사이즈를 홀수로 적습니다.
테스트에 사용된 이미지들











처참한 결과
직접 만든 파이썬을 구동해보았습니다.
이미지파일의 이름을 변경하여 결과가 적히게 했는데...
결과는 처참했습니다. (되는게 없네?....)

하나하나 가우시안 처리를 다 해줬음에도 불구하고, OCR은 글자를 읽지 못했다고 합니다...
222는 그렇다고 치더라도 '난소이발아', '뺀빼삐'는 도대체가......어째서 저런게 나온지 이해가 안되는군요..
마치며
여러가지 주저리 했지만, 그래도 많이 재밌는 프로젝트였고
무인 주차장에 있는 번호판 판독기가 존경스러워 보이게 되는 프로젝트 였습니다. ㅠㅠ
'스터디 > Etc' 카테고리의 다른 글
| 모바일 앱 개발 방법들 (네이티브,웹앱,하이브리드,크로스플랫폼,WPA) (2) | 2021.12.25 |
|---|---|
| 앱 개발 크로스플랫폼 트랜드 (2) | 2021.08.01 |
| [Windows] .Net Framework 종류 (WinForm, WPF, WinRT, UWP) (0) | 2021.07.09 |
| C# 자료형과 Java 자료형 크기 비교 (0) | 2019.10.08 |
| SourceTree에서 FileMerge(파일머지) 실행 안 될때 (0) | 2018.02.08 |

댓글